Aquí tienes el borrador de la publicación del blog para My Core Pick.
Preparando la IA para el negocio: Cómo RAG conecta los LLM con tus datos en tiempo real
Seamos honestos por un segundo.
A estas alturas, todos hemos jugado con ChatGPT o Claude.
Le hemos pedido que escriba un poema, depure algún código o resuma un correo electrónico genérico. Se siente como magia.
Pero en el momento en que intentas usarlo para negocios serios, la magia a menudo se desvanece.
Le preguntas sobre tus proyecciones de ventas del tercer trimestre (Q3) y alucina una cifra.
Le preguntas sobre una cláusula específica en tu contrato de proveedor exclusivo y se disculpa porque no tiene acceso a tus archivos.
Este es el problema de la "Última Milla" de la IA Generativa.
Los Grandes Modelos de Lenguaje (LLM) son increíblemente inteligentes, pero son inteligentes en términos generales. Saben todo sobre internet hasta su fecha límite de entrenamiento, pero no saben absolutamente nada sobre tu negocio.
Entonces, ¿cómo arreglamos esto?
¿Gastamos millones reentrenando un modelo? No.
Usamos una arquitectura llamada Generación Aumentada por Recuperación, o RAG (por sus siglas en inglés).
Hoy, te guiaré a través de cómo funciona RAG, por qué es el puente para hacer que la IA esté lista para el negocio y cómo conecta potentes LLM a tus datos en tiempo real.
El problema con la IA "Congelada"

Para entender por qué RAG es necesario, primero tenemos que mirar las limitaciones de un LLM estándar.
Piensa en un LLM como una nueva contratación brillante que ha leído todos los libros de la Biblioteca del Congreso.
Es elocuente, conocedor y puede razonar a través de problemas complejos.
Sin embargo, esta nueva contratación ha estado viviendo en una cueva durante el último año.
No ha leído el manual de tu empresa.
No tiene acceso a tu historial de correos electrónicos.
No sabe que cambiaste tu modelo de precios ayer por la mañana.
El corte de conocimiento
Los LLM están "congelados" en el tiempo.
Si un modelo fue entrenado con datos que terminan en 2023, no tiene concepto de los eventos que ocurren en 2024.
Para un negocio que opera en mercados en tiempo real, esta latencia es inaceptable.
El peligro de las alucinaciones
Cuando un LLM no sabe la respuesta, intenta ser útil.
Desafortunadamente, "intentar ser útil" a menudo se parece a inventar cosas.
En un contexto de escritura creativa, a esto lo llamamos imaginación.
En un contexto empresarial —como legal o finanzas— lo llamamos un riesgo.
Necesitamos una forma de forzar a la IA a apegarse a los hechos contenidos en nuestros propios datos.
¿Qué es exactamente RAG?
La Generación Aumentada por Recuperación (RAG) es un marco que recupera datos de tu base de conocimientos externa y fundamenta el LLM con ellos.
Me gusta usar la analogía del "Examen a libro abierto".
Usar un LLM estándar es como obligar a un estudiante a tomar un examen confiando solo en su memoria.
Si no recuerdan el hecho específico, podrían adivinar.
RAG es como permitir que ese estudiante tome un examen a libro abierto.
Antes de responder la pregunta, al estudiante se le permite ir a un libro de texto específico (los datos de tu empresa), encontrar la página relevante, leerla y luego responder la pregunta basándose en lo que acaba de leer.
El estudiante (el LLM) proporciona el razonamiento y las habilidades lingüísticas.
El libro de texto (tu base de datos) proporciona los hechos.
Esta combinación crea un sistema que es tanto elocuente como preciso.
Cómo funciona RAG internamente
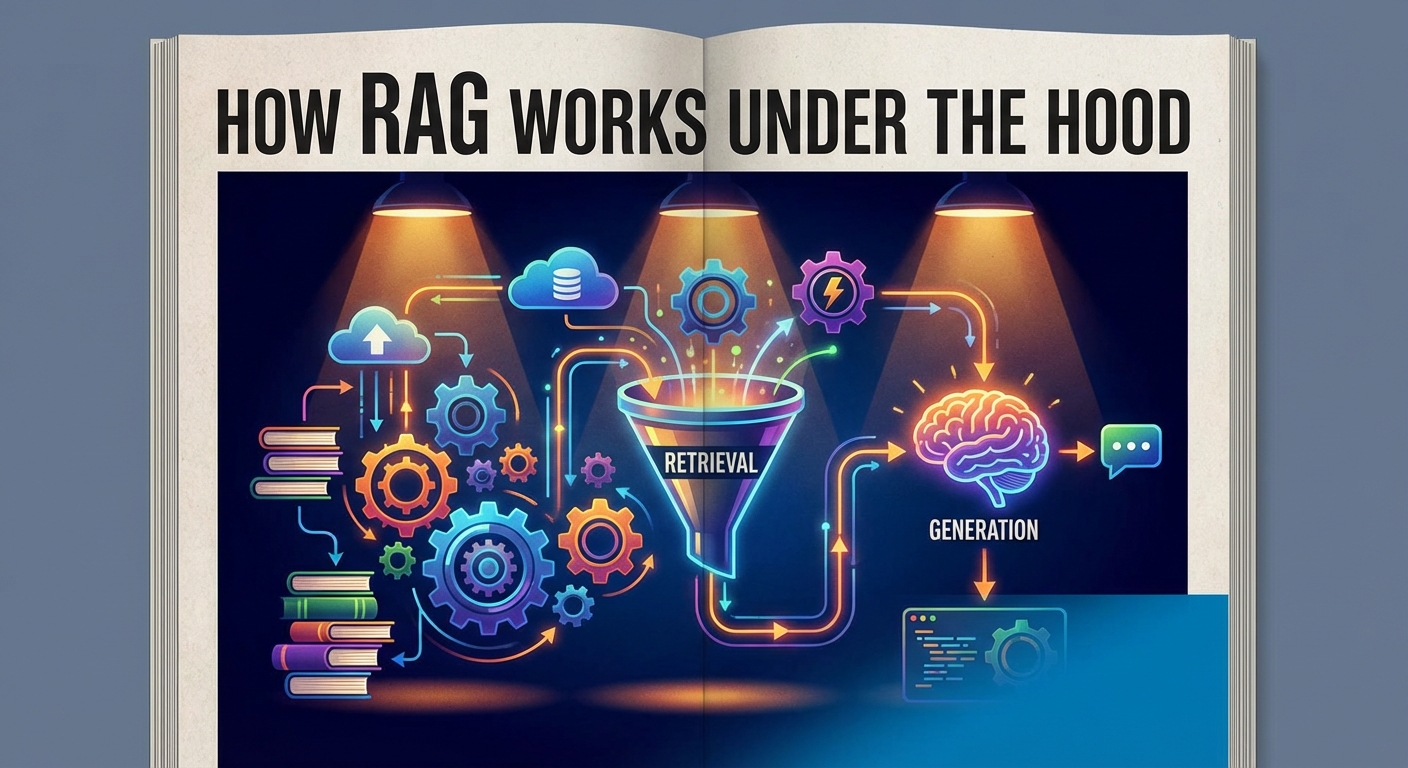
Implementar RAG puede sonar técnico, pero el flujo de trabajo es bastante lógico.
Conecta tus fuentes de datos —PDFs, bases de datos SQL, correos electrónicos, historial de Slack— a la IA.
Aquí está el proceso de tres pasos de cómo construimos esto realmente.
1. Ingestión e Indexación (La Biblioteca)
Primero, tenemos que preparar tus datos.
Los LLM no pueden simplemente "leer" toda tu base de datos en un segundo.
Tomamos tus documentos y los dividimos en piezas más pequeñas, llamadas "fragmentos" (chunks).
Luego, convertimos estos fragmentos en Incrustaciones Vectoriales (Vector Embeddings).
Esta es la salsa secreta.
Una incrustación convierte el texto en una larga cadena de números (un vector) que representa el significado del texto, no solo las palabras clave.
Almacenamos estos vectores en una Base de Datos Vectorial especializada.
2. Recuperación (La Búsqueda)
Cuando un usuario hace una pregunta, no la enviamos directamente al LLM.
Primero, el sistema convierte la pregunta del usuario también en un vector.
Luego busca en tu Base de Datos Vectorial fragmentos de texto que sean semánticamente similares a la pregunta.
Si preguntas: "¿Por qué se retrasó el proyecto del Q3?", el sistema busca vectores relacionados con "Q3", "retrasos" y nombres de proyectos específicos.
Recupera los párrafos más relevantes de tus documentos internos.
3. Generación (La Respuesta)
Ahora viene el traspaso.
El sistema toma la pregunta del usuario Y los párrafos recuperados (contexto).
Los empaqueta juntos en un prompt que se ve algo así:
"Usando solo el contexto proporcionado a continuación, responda la pregunta del usuario."
El LLM lee el contexto que encontraste y genera la respuesta.
Cita la fuente, asegurando que sepas exactamente de dónde vino la información.
Por qué RAG supera al Ajuste Fino (Fine-Tuning)
Una pregunta común que escucho de los clientes es: "¿No deberíamos simplemente ajustar (fine-tune) el modelo con nuestros datos?"
Usualmente, la respuesta es no.
El ajuste fino es el proceso de entrenar más un modelo para cambiar su comportamiento o estilo.
Es excelente para enseñar a un modelo a hablar con la voz de tu marca o escribir código en un formato específico.
Pero es terrible para la retención de conocimientos.
El costo de las actualizaciones
Si ajustas un modelo con tus datos, ese conocimiento se congela nuevamente en el momento en que dejas de entrenar.
Para actualizar el modelo con nuevos datos, tienes que volver a entrenarlo.
Esto es costoso, lento y computacionalmente pesado.
El problema de la Caja Negra
Cuando un modelo ajustado responde una pregunta, no puedes rastrear fácilmente por qué dio esa respuesta.
Está enterrado en algún lugar de los pesos neuronales del modelo.
Con RAG, tienes transparencia total.
Puedes ver exactamente qué fragmentos de documentos fueron recuperados.
Si la respuesta es incorrecta, puedes verificar si el documento recuperado estaba desactualizado.
Hace que la depuración y auditoría de tu IA sean significativamente más fáciles.
Los beneficios comerciales de RAG
Entonces, ¿por qué debería importarte esta arquitectura?
Porque convierte a la IA de un juguete en una herramienta.
Aquí están los cuatro beneficios principales que vemos cuando las empresas implementan RAG.
1. Precisión en tiempo real
RAG se conecta a tus datos en vivo.
Si actualizas un documento de política en tu base de datos, la IA lo sabe de inmediato.
No hay tiempo de inactividad por entrenamiento.
Tu IA siempre está tan actual como tu base de datos.
2. Seguridad y privacidad de los datos
Este es un punto importante para los clientes empresariales.
Con RAG, tus datos propietarios permanecen en tu base de datos vectorial controlada.
No se utilizan para entrenar el modelo público (como GPT-4).
Solo estás enviando pequeños fragmentos de texto a la API para su procesamiento, no toda tu propiedad intelectual.
También puedes implementar controles de permisos.
Si un empleado junior pregunta a la IA sobre los salarios del CEO, el sistema de recuperación puede bloquear el acceso a esos documentos según los roles de usuario.
3. Reducción de alucinaciones
Al limitar al LLM a "usar solo el contexto proporcionado", reduces drásticamente la posibilidad de que la IA invente cosas.
Si el sistema no puede encontrar la respuesta en tus documentos, puede programarse para decir: "No lo sé".
En los negocios, "no lo sé" es infinitamente mejor que una mentira dicha con confianza.
4. Eficiencia de costos
Los LLM cobran por "token" (conteo de palabras).
Alimentar un manual completo de 100 páginas en un LLM para cada pregunta es costoso.
RAG solo alimenta los 2 o 3 párrafos relevantes necesarios para responder la pregunta específica.
Esto mantiene bajos tus costos de API y rápidos tus tiempos de respuesta.
Casos de uso en el mundo real
RAG no es solo teoría; está impulsando las mejores aplicaciones de IA que vemos hoy.
Así es como diferentes departamentos lo están utilizando ahora mismo.
Atención al cliente
Imagina un chatbot que realmente funcione.
En lugar de respuestas genéricas, un bot habilitado con RAG extrae respuestas de tus manuales técnicos específicos, historial de tickets pasados y datos de envío actuales.
Puede decir: "Veo que tu pedido #123 está retrasado debido al clima", en lugar de solo listar tu política de reembolso.
Legal y Cumplimiento
Los abogados están usando RAG para consultar miles de contratos al instante.
"Muéstrame todos los contratos que tienen fecha de renovación en 2024 y contienen una cláusula de Fuerza Mayor".
El sistema recupera las cláusulas exactas y resume el riesgo.
Gestión del Conocimiento Interno
Todos odiamos buscar en la Intranet de la empresa.
La búsqueda por palabras clave rara vez funciona bien.
Con RAG, puedes construir un "CompanyGPT" interno.
Los nuevos empleados pueden preguntar: "¿Cómo configuro mi VPN?" o "¿Quién es el punto de contacto para el proyecto de marketing?".
La IA recupera la respuesta de la wiki de RR.HH. o del historial de Slack al instante.
Empezando con RAG
Implementar RAG es el movimiento de mayor impacto que puedes hacer en tu estrategia de IA hoy.
Cierra la brecha entre el increíble poder lingüístico de los LLM y el valor específico y exclusivo de tus datos.
No necesitas comenzar indexando cada documento en tu empresa.
Empieza pequeño.
Elige un conjunto de datos, tal vez tus preguntas frecuentes de atención al cliente o tu documentación técnica.
Cárgalo en una base de datos vectorial.
Conéctalo a un LLM.
Observa la diferencia que hace cuando la IA realmente sabe de lo que está hablando.
Estamos pasando de la fase de exageración de la IA a la fase de utilidad.
RAG es la infraestructura que hace posible esa utilidad.
Es hora de dejar de chatear con la IA y empezar a trabajar con ella.