Here is a blog post tailored for My Core Pick.
「掘り起こす」のはやめよう、これからは「尋ねる」時代だ:RAGはいかにして企業の非構造化データを変革するか
あるシナリオを想像してみてください。火曜日の午後2時のことです。
あなたは、3年前に署名されたベンダー契約書にある特定の条項を探しています。
それが存在することは知っています。メールのやり取りも覚えています。上司がSlackで「いいね」をしたことも覚えています。
しかし、見つかりません。
「ベンダー契約書」で検索しても、役に立つものは出てきません。ベンダー名で検索すると、400件もの結果が表示されます。
PDFを一つずつ開き始めます。アーカイブされたメールを掘り返します。すでに持っているはずの情報を見つけるためだけに、45分も無駄にしてしまいます。
これが「発掘(Digging)のパラダイム」です。率直に言って、これは企業の生産性を殺しています。
私たちはデータの海に溺れながら、インサイト(洞察)に飢えているのです。
しかし今、変化が起きています。「掘り起こす」ことから「尋ねる」ことへの移行です。
それは RAG(Retrieval-Augmented Generation:検索拡張生成) と呼ばれ、エンタープライズデータ管理において、検索バーの登場以来、最も重要な進歩と言えます。
問題点:非構造化データという氷山
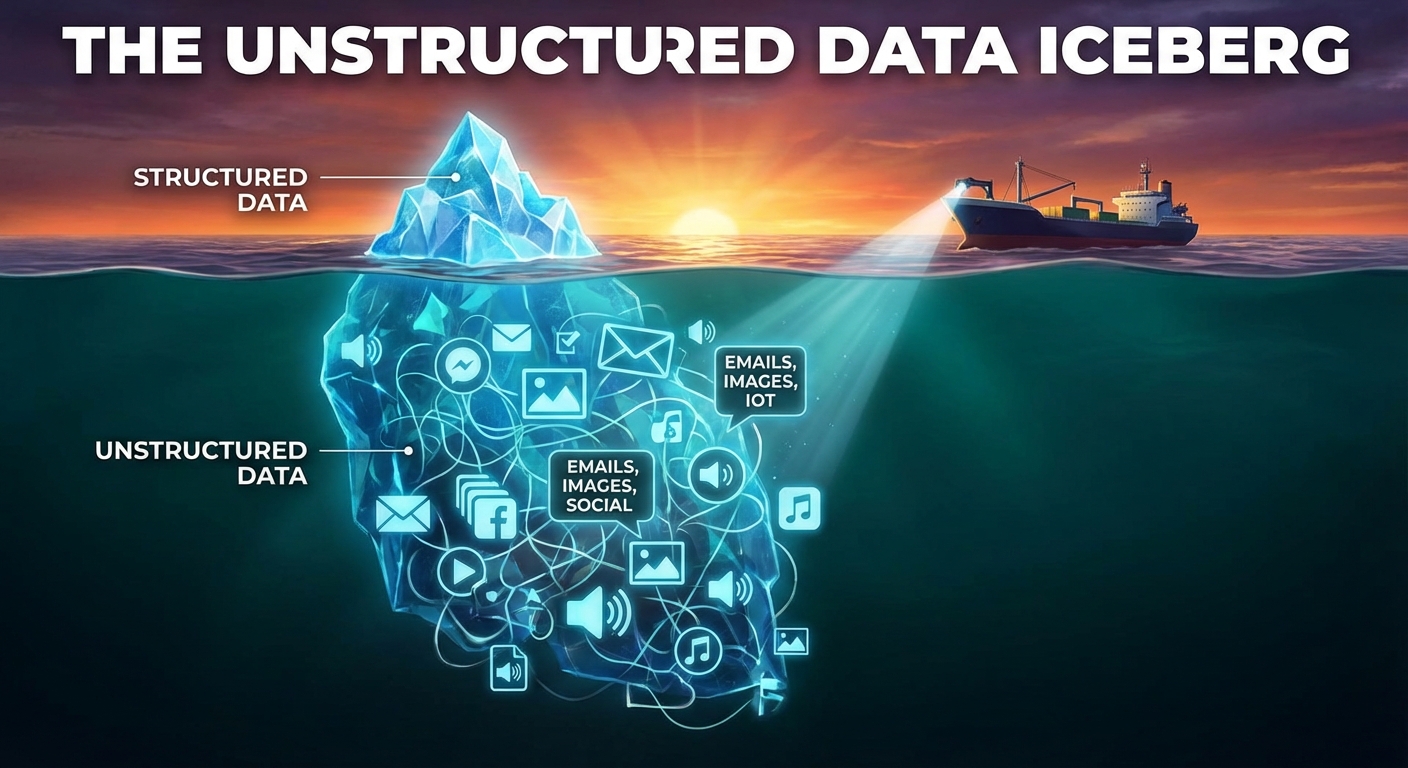
夜も眠れなくなるような統計があります。
一般的に、企業データの約80%は「非構造化データ」です。
構造化データは簡単です。Excelシート、SQLデータベース、CRMのフィールドに存在します。行と列に収まり、整然としています。
一方、非構造化データは厄介です。
水面下に潜むもの
非構造化データには、PDF、社内Wiki、長いメールスレッド、Slackの会話、動画の書き起こし、スライド資料などが含まれます。
これらこそが、実際の業務が行われている場所であり、文脈(コンテキスト)が存在する場所です。
しかし、従来の検索ツールはこれを読むのが苦手です。
標準的な企業内検索はキーワードに依存しています。文書に含まれる正確なキーワードを入力しなければ、見つけることはできません。
それはまるで、すべての表紙が剥ぎ取られた図書館で本を探そうとするようなものです。
汎用AIの限界
そこで、「ChatGPTを使えばいいじゃないか?」と思うかもしれません。
一般公開されている大規模言語モデル(LLM)は素晴らしいものですが、ビジネスにおいては2つの致命的な欠陥があります。
第一に、それらはあなたの秘密を知りません。社内メモや独自のコードを読んだことがないのです。
第二に、それらは「ハルシネーション(もっともらしい嘘)」を起こします。答えを知らない場合、あなたを喜ばせるためだけに答えをでっち上げることがあります。
ビジネスの文脈において、ハルシネーションは単なる愛嬌ではなく、法的責任(liability)に関わる問題です。
ここで、RAGがそのギャップを埋めます。
RAGの登場:「持ち込み可」のテスト

専門用語を一旦脇に置いて考えてみましょう。
RAG(検索拡張生成)を理解するために、学生時代を思い出してください。
標準的なLLM(一般的なGPT-4など)を使用することは、記憶力だけでテストを受けるようなものです。
その学生は賢く、たくさんの本を読んでいます。しかし、今朝起こった特定の出来事について尋ねても、答えることはできません。彼らの記憶はある時点で止まっているからです。
AIに「カンニングペーパー」を与える
RAGはテストのルールを変えます。
RAGは、学生に「教科書持ち込み可(オープンブック)」のテストを受けさせるようなものです。
あなたが質問をすると、AIはトレーニングされた記憶だけに頼ることはしません。
代わりに、AIは一旦立ち止まります。そして会社の「非公開の書庫」へ走り、あなたの質問に関連する正確な文書を取り出します。
そして、それらを即座に読み込みます。
最後に、それらの文書のみに基づいて回答を作成します。
その結果
データソースを引用するため、回答は正確です。
5分前にアップロードしたものを読み込むため、情報は最新です。
そして極めて重要なことに、「掘り起こす」作業が終わります。あなたが文書を見つける必要はありません。ただ質問すればいいのです。
仕組み:その舞台裏

技術的な話をしすぎるつもりはありません。しかし、メカニズムを理解することで、その価値が見えてきます。
RAGは魔法ではありません。3つのステップからなるワークフローです。
1. インデックス作成(ベクトルデータベース)
まず、PDF、HTMLファイル、テキストドキュメントなど、散らかった非構造化データをすべて取り込みます。
それらを小さな「チャンク(塊)」に分割します。
次に、そのチャンクを「ベクトル」に変換します。
ベクトルとは、単なるキーワードではなく、テキストの意味を表す数字の羅列です。
例えば、キーワード検索では「車」と「自動車」は別物として扱われますが、ベクトル検索ではこれらが意味的に同一であることを理解します。
これらのベクトルを専用のデータベースに保存します。
2. 検索(探索)
さて、あなたが「契約社員のリモートワークに関する規定はどうなっている?」と入力したとします。
システムはあなたの質問をベクトルに変換します。
そしてデータベースの中から、あなたの質問と数学的に類似したテキストのチャンクを探します。
その結果、会社規定のハンドブックから最も関連性の高い3〜5個の段落を取得(Retrieve)します。
3. 生成(統合)
ここが面白い部分です。
システムはLLMに対して、次のようなプロンプト(指示)を送ります:
「ユーザーの質問:リモートワークの規定は何ですか? データベースで見つかったコンテキストはこちらです:[取得した段落を挿入]。このコンテキストのみを使用してユーザーに回答してください。」
LLMは要約者および統合者として機能します。
そして、ソースとなるPDFへの引用リンクを添えて、分かりやすい言葉で回答を生成します。
なぜこれがすべてを変えるのか
この技術は、従業員体験を根本的なレベルで変革すると私は信じています。
私たちは「検索する人(Searchers)」から「知っている人(Knowers)」へとシフトするのです。
現実世界でこれがどのように展開されるか、3つの具体的な例を挙げましょう。
1. 「ハルシネーション」への恐怖の終焉
企業へのAI導入における最大の障壁の一つは「信頼」です。
経営陣は、AIが財務数値を勝手に作り出すことを恐れています。
RAGを使えば、AIにその根拠(ワーク)を示させることができます。
もしシステムが取得した文書の中に答えを見つけられなければ、「分かりません」と答えるようにプログラムできます。適当なことを言うことはありません。
この「根拠に基づく(Grounding)」特性により、AIはビジネスで安全に使えるものになります。
2. 即戦力化(オンボーディングの瞬時化)
入社初日の新入社員を想像してください。
通常、彼らは数週間かけて同僚の肩を叩き、「有給休暇はどう申請するのですか?」「VPNはどう設定するのですか?」と聞いて回ります。
RAG対応のチャットボットがあれば、システムに尋ねるだけで済みます。
システムはConfluenceのページ、人事部作成のPDF、IT部門のSlackチャンネルの履歴から情報を引き出します。
新入社員は即座に回答を得られ、シニアエンジニアの作業が中断されることもありません。
3. 劇的に進化するカスタマーサポート
サポート担当者は、おそらくドキュメントの山に溺れています。
顧客から複雑な技術的質問を受けると、担当者は通常、保留にしてマニュアルを掘り返します。
RAGがあれば、担当者は質問を入力するだけです。システムは技術マニュアル、リリースノート、バグ報告書を取得します。
そして数秒で、提案回答を生成します。
解決までの時間を50%以上短縮することも夢ではありません。
導入に向けて:すべてを一度にやろうとしない
もし導入を考えているなら、いくつかアドバイスがあります。
すべてを一度にインデックス化しようとしないでください。
RAGは強力ですが、「ゴミを入れればゴミが出てくる(Garbage In, Garbage Out)」という原則には逆らえません。
価値の高いデータから始める
特定のドメインを選びましょう。人事規定は始めるのに最適な場所です。あるいは、特定製品の技術文書も良いでしょう。
そのデータをクリーンアップしてください。文書が最新であることを確認してください。
もし2019年の古い規定と2024年の新しい規定が混在したままシステムに読み込ませれば、AIは混乱します。
セキュリティは最優先事項
これは非常に重要です。
CEOの個人的なメールや給与計算のスプレッドシートをインデックス化し、そのチャットインターフェースをインターン生に開放してしまえば、大問題になります。
RAGシステムは、アクセス制御リスト(ACL)を尊重しなければなりません。
検索ステップでは、その特定のユーザーが閲覧権限を持つ文書だけを取得するようにする必要があります。
このステップは絶対に省略しないでください。
未来は「対話型」にある
私たちは、ソフトウェアのインターフェースが単なる自然言語になる世界へと向かっています。
メニューを操作することも、列をフィルタリングすることも、高度な検索構文を駆使することもなくなるでしょう。
ただ、話しかけるだけです。
「先週の売上傾向を、第3四半期の予測と比較して見せて。」
「これら5つの法的契約書に記載されているリスクを要約して。」
「エンジニアリングチームの更新情報に基づいて、遅延を説明するメールの下書きを作成して。」
RAGは、これを可能にするエンジンです。
それは、埃をかぶり、構造化されておらず、忘れ去られていたデータを、生きた知識ベースへと変えます。
だから、フォルダを掘り返すのはもうやめましょう。たった一文を見つけるために50ページのPDFを読むのもやめましょう。
問いかけ始めましょう。
あなたのデータは、答える準備ができています。