Here is the blog post draft for My Core Pick.
Making AI Business-Ready: How RAG Connects LLMs to Your Real-Time Data
Let’s be honest for a second.
We have all played around with ChatGPT or Claude by now.
We’ve asked it to write a poem, debug some code, or summarize a generic email. It feels like magic.
But the moment you try to use it for serious business, the magic often fades.
You ask it about your Q3 sales projections, and it hallucinates a number.
You ask it about a specific clause in your proprietary vendor contract, and it apologizes because it doesn’t have access to your files.
This is the "Last Mile" problem of Generative AI.
Large Language Models (LLMs) are incredibly smart, but they are generally smart. They know everything about the internet up to their training cutoff, but they know absolutely nothing about your business.
So, how do we fix this?
Do we spend millions retraining a model? No.
We use an architecture called Retrieval-Augmented Generation, or RAG.
Today, I’m going to walk you through how RAG works, why it is the bridge to making AI business-ready, and how it connects powerful LLMs to your real-time data.
The Problem with "Frozen" AI

To understand why RAG is necessary, we first have to look at the limitations of a standard LLM.
Think of an LLM like a brilliant new hire who has read every book in the Library of Congress.
They are articulate, knowledgeable, and can reason through complex problems.
However, this new hire has been living in a cave for the last year.
They haven't read your company handbook.
They don't have access to your email history.
They don't know that you changed your pricing model yesterday morning.
The Knowledge Cutoff
LLMs are "frozen" in time.
If a model was trained on data ending in 2023, it has no concept of events happening in 2024.
For a business operating in real-time markets, this latency is unacceptable.
The Hallucination Hazard
When an LLM doesn’t know the answer, it tries to be helpful.
Unfortunately, "trying to be helpful" often looks like making things up.
In a creative writing context, we call this imagination.
In a business context—like legal or finance—we call this a liability.
We need a way to force the AI to stick to the facts contained in our own data.
What Exactly is RAG?
Retrieval-Augmented Generation (RAG) is a framework that retrieves data from your external knowledge base and grounds the LLM with it.
I like to use the "Open Book Exam" analogy.
Using a standard LLM is like forcing a student to take a test relying only on their memory.
If they don't remember the specific fact, they might guess.
RAG is like allowing that student to take an open-book exam.
Before answering the question, the student is allowed to go to a specific textbook (your company data), find the relevant page, read it, and then answer the question based on what they just read.
The student (the LLM) provides the reasoning and language skills.
The textbook (your database) provides the facts.
This combination creates a system that is both articulate and accurate.
How RAG Works Under the Hood
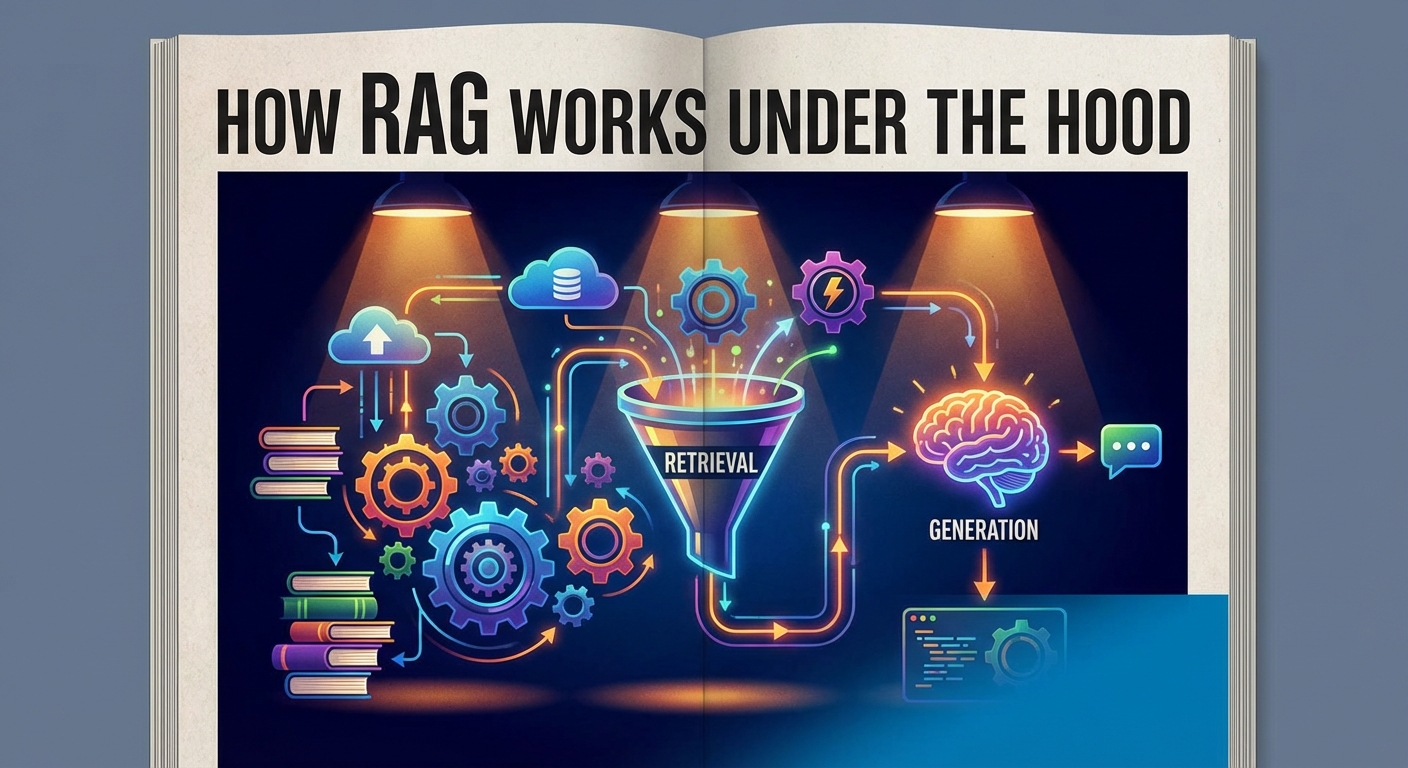
Implementing RAG might sound technical, but the workflow is actually quite logical.
It connects your data sources—PDFs, SQL databases, emails, Slack history—to the AI.
Here is the three-step process of how we actually build this.
1. Ingestion and Indexing (The Library)
First, we have to prepare your data.
LLMs can't just "read" your entire database in one second.
We take your documents and break them down into smaller pieces, called "chunks."
Then, we convert these chunks into Vector Embeddings.
This is the secret sauce.
An embedding turns text into a long string of numbers (a vector) that represents the meaning of the text, not just the keywords.
We store these vectors in a specialized Vector Database.
2. Retrieval (The Search)
When a user asks a question, we don't send it straight to the LLM.
First, the system converts the user's question into a vector as well.
It then searches your Vector Database for chunks of text that are semantically similar to the question.
If you ask, "Why is the Q3 project delayed?" the system looks for vectors related to "Q3," "delays," and specific project names.
It retrieves the most relevant paragraphs from your internal docs.
3. Generation (The Answer)
Now comes the hand-off.
The system takes the user's question AND the retrieved paragraphs (context).
It packages them together into a prompt that looks something like this:
"Using only the context provided below, answer the user's question."
The LLM reads the context you found and generates the answer.
It cites the source, ensuring you know exactly where the information came from.
Why RAG Beats Fine-Tuning
A common question I hear from clients is: "Shouldn't we just fine-tune the model on our data?"
Usually, the answer is no.
Fine-tuning is the process of further training a model to change its behavior or style.
It is great for teaching a model to speak in your brand voice or write code in a specific format.
But it is terrible for knowledge retention.
The Cost of Updates
If you fine-tune a model on your data, that knowledge is frozen again the moment you stop training.
To update the model with new data, you have to re-train it.
This is expensive, slow, and computationally heavy.
The Black Box Problem
When a fine-tuned model answers a question, you can't easily trace why it gave that answer.
It’s buried somewhere in the model's neural weights.
With RAG, you have full transparency.
You can see exactly which document chunks were retrieved.
If the answer is wrong, you can check if the retrieved document was outdated.
It makes debugging and auditing your AI significantly easier.
The Business Benefits of RAG
So, why should you care about this architecture?
Because it turns AI from a toy into a tool.
Here are the four main benefits we see when businesses implement RAG.
1. Real-Time Accuracy
RAG connects to your live data.
If you update a policy document in your database, the AI knows about it immediately.
There is no training downtime.
Your AI is always as current as your database.
2. Data Security and Privacy
This is a big one for enterprise clients.
With RAG, your proprietary data stays in your controlled vector database.
It is not used to train the public model (like GPT-4).
You are only sending small snippets of text to the API for processing, not your entire intellectual property.
You can also implement permission controls.
If a junior employee asks the AI about CEO salaries, the retrieval system can block access to those documents based on user roles.
3. Reduced Hallucinations
By constraining the LLM to "only use the provided context," you drastically reduce the chance of the AI making things up.
If the system can't find the answer in your documents, it can be programmed to say, "I don't know."
In business, "I don't know" is infinitely better than a confident lie.
4. Cost Efficiency
LLMs charge by the "token" (word count).
Feeding an entire 100-page manual into an LLM for every question is expensive.
RAG only feeds the 2 or 3 relevant paragraphs needed to answer the specific question.
This keeps your API costs low and your response times fast.
Real-World Use Cases
RAG isn't just theory; it's powering the best AI applications we see today.
Here is how different departments are using it right now.
Customer Support
Imagine a chatbot that actually works.
Instead of generic responses, a RAG-enabled bot pulls answers from your specific technical manuals, past ticket history, and current shipping data.
It can say, "I see your order #123 is delayed due to weather," rather than just listing your refund policy.
Legal and Compliance
Lawyers are using RAG to query thousands of contracts instantly.
"Show me all contracts that have a renewal date in 2024 and contain a Force Majeure clause."
The system retrieves the exact clauses and summarizes the risk.
Internal Knowledge Management
We all hate searching the company Intranet.
Keyword search rarely works well.
With RAG, you can build an internal "CompanyGPT."
New employees can ask, "How do I set up my VPN?" or "Who is the point of contact for the marketing project?"
The AI retrieves the answer from the HR wiki or Slack history instantly.
Getting Started with RAG
Implementing RAG is the single most high-leverage move you can make in your AI strategy today.
It bridges the gap between the incredible linguistic power of LLMs and the specific, proprietary value of your data.
You don't need to start by indexing every document in your company.
Start small.
Pick one dataset—maybe your customer support FAQs or your technical documentation.
Load it into a vector database.
Connect it to an LLM.
See the difference it makes when the AI actually knows what it's talking about.
We are moving past the hype phase of AI and into the utility phase.
RAG is the infrastructure that makes that utility possible.
It’s time to stop chatting with AI, and start working with it.