Here is the blog post draft for My Core Pick.
让 AI 为商业应用做好准备:RAG 如何将 LLM 连接到您的实时数据
说句实话。
到现在为止,我们都玩过 ChatGPT 或 Claude 了。
我们让它写过诗、调试过代码,或者总结过那种通用的邮件。这感觉就像魔法一样。
但当你试图将其用于严肃的商业用途时,这种魔法往往会消失。
你问它关于第三季度的销售预测,它会胡编乱造一个数字(产生幻觉)。
你问它关于你们专有供应商合同中的某个特定条款,它会道歉,因为它无法访问你的文件。
这就是生成式 AI 的“最后一公里”问题。
大语言模型(LLMs)非常聪明,但它们是通用的聪明。它们知道截止到训练时间为止互联网上的一切,但它们对你的业务一无所知。
那么,我们该如何解决这个问题?
我们要花费数百万美元重新训练一个模型吗?不。
我们使用一种称为 检索增强生成(Retrieval-Augmented Generation),简称 RAG 的架构。
今天,我将带你了解 RAG 是如何工作的,为什么它是让 AI 为商业应用做好准备的桥梁,以及它如何将强大的 LLM 连接到你的实时数据。
“冻结”AI 的问题

要理解为什么 RAG 是必要的,我们首先必须看看标准 LLM 的局限性。
把 LLM 想象成一个阅读了国会图书馆每一本书的才华横溢的新员工。
他们口齿伶俐,知识渊博,能够推理复杂的问题。
然而,这位新员工过去一年一直住在山洞里。
他们没有读过你的员工手册。
他们无法访问你的电子邮件历史记录。
他们不知道你昨天早上更改了定价模型。
知识截止点
LLM 在时间上是“冻结”的。
如果一个模型的训练数据截止于 2023 年,它对 2024 年发生的事件就毫无概念。
对于在实时市场中运营的企业来说,这种延迟是不可接受的。
幻觉风险
当 LLM 不知道答案时,它会试图提供帮助。
不幸的是,“试图提供帮助”往往表现为编造事实。
在创意写作的语境下,我们称之为想象力。
在商业语境下——比如法律或金融——我们称之为责任隐患。
我们需要一种方法来强制 AI 坚持使用我们要数据中包含的事实。
RAG 到底是什么?
检索增强生成(RAG)是一个框架,它从你的外部知识库中检索数据,并以此为基础来规范 LLM 的回答。
我喜欢用“开卷考试”来做类比。
使用标准的 LLM 就像强迫学生仅仅依靠记忆去考试。
如果他们不记得具体的某种事实,他们可能会瞎猜。
RAG 就像允许那个学生参加开卷考试。
在回答问题之前,学生被允许去查阅特定的教科书(你的公司数据),找到相关的页面,阅读它,然后根据刚才读到的内容回答问题。
学生(LLM)提供推理和语言能力。
教科书(你的数据库)提供事实。
这种结合创造了一个既能言善辩又准确无误的系统。
RAG 的幕后工作原理
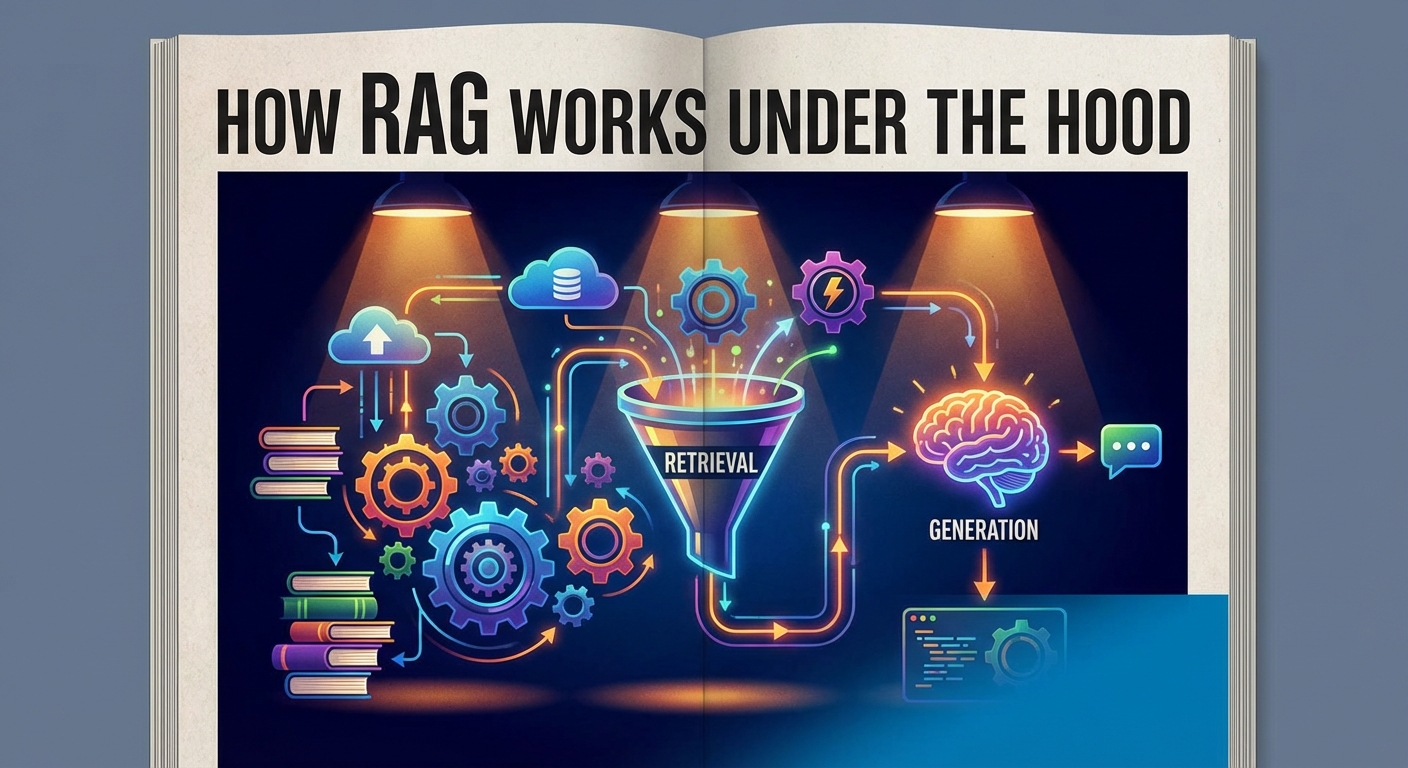
实施 RAG 听起来可能很技术性,但其工作流程实际上非常符合逻辑。
它将你的数据源——PDF、SQL 数据库、电子邮件、Slack 历史记录——连接到 AI。
以下是我们实际构建它的三个步骤。
1. 摄入与索引(图书馆)
首先,我们必须准备你的数据。
LLM 无法在一秒钟内“阅读”你的整个数据库。
我们将你的文档分解成更小的部分,称为“块”(chunks)。
然后,我们将这些块转换为 向量嵌入(Vector Embeddings)。
这是核心秘诀。
嵌入将文本转换成一长串数字(向量),代表文本的含义,而不仅仅是关键词。
我们将这些向量存储在专门的 向量数据库 中。
2. 检索(搜索)
当用户提出问题时,我们不会直接将其发送给 LLM。
首先,系统也会将用户的问题转换为向量。
然后,它在你的向量数据库中搜索与问题语义相似的文本块。
如果你问,“为什么 Q3 项目推迟了?”系统会寻找与“Q3”、“推迟”和特定项目名称相关的向量。
它会从你的内部文档中检索出最相关的段落。
3. 生成(回答)
现在到了交接环节。
系统获取用户的问题以及检索到的段落(上下文)。
它将它们打包成一个看起来像这样的提示词(prompt):
“仅使用下面提供的上下文,回答用户的问题。”
LLM 阅读你找到的上下文并生成答案。
它会引用来源,确保你确切知道信息来自哪里。
为什么 RAG 胜过微调
我经常从客户那里听到的一个问题是:“难道我们不应该就在我们的数据上微调模型吗?”
通常,答案是否定的。
微调是进一步训练模型以改变其行为或风格的过程。
它非常适合教模型以你的品牌语调说话或以特定格式编写代码。
但它在知识保留方面表现糟糕。
更新成本
如果你在你的数据上微调一个模型,当你停止训练的那一刻,知识又被冻结了。
要用新数据更新模型,你必须重新训练它。
这既昂贵、缓慢,计算量又大。
黑盒问题
当微调后的模型回答问题时,你很难追踪它为什么给出那个答案。
它被埋在模型神经网络权重的某个地方。
使用 RAG,你拥有完全的透明度。
你可以确切地看到检索了哪些文档块。
如果答案是错误的,你可以检查检索到的文档是否已过时。
这使得调试和审计你的 AI 变得容易得多。
RAG 的商业利益
那么,你为什么要关心这个架构?
因为它将 AI 从玩具变成了工具。
以下是企业实施 RAG 时我们看到的四个主要好处。
1. 实时准确性
RAG 连接到你的实时数据。
如果你更新了数据库中的政策文档,AI 会立即知道。
没有训练停机时间。
你的 AI 始终与你的数据库一样保持最新。
2. 数据安全与隐私
这对企业客户来说是一个重点。
使用 RAG,你的专有数据保留在受控的向量数据库中。
它不会用于训练公共模型(如 GPT-4)。
你只是将一小段文本发送到 API 进行处理,而不是你的整个知识产权。
你还可以实施权限控制。
如果初级员工向 AI 询问 CEO 的薪水,检索系统可以根据用户角色阻止访问这些文档。
3. 减少幻觉
通过限制 LLM “仅使用提供的上下文”,你大大降低了 AI 编造内容的可能性。
如果系统在你的文档中找不到答案,它可以被编程为说“我不知道”。
在商业中,“我不知道”比自信的谎言要好得多。
4. 成本效益
LLM 按“Token”(字数/词元)收费。
针对每个问题将整本 100 页的手册输入 LLM 是昂贵的。
RAG 仅提供回答特定问题所需的 2 或 3 个相关段落。
这保持了较低的 API 成本和较快的响应时间。
现实世界的用例
RAG 不仅仅是理论;它正在为我们今天看到的最好的 AI 应用程序提供动力。
以下是不同部门目前正在使用它的方式。
客户支持
想象一个真正有效的聊天机器人。
与其给出通用的回复,启用了 RAG 的机器人会从你特定的技术手册、过去的工单历史和当前的运输数据中提取答案。
它可以说,“我看到您的订单 #123 因天气原因延误了”,而不仅仅是列出您的退款政策。
法律与合规
律师们正在使用 RAG 即时查询数千份合同。
“给我看所有续约日期在 2024 年且包含不可抗力条款的合同。”
系统会检索确切的条款并总结风险。
内部知识管理
我们都讨厌搜索公司内网。
关键词搜索很少能很好地工作。
使用 RAG,你可以建立一个内部的“CompanyGPT”。
新员工可以问,“我如何设置 VPN?”或者“谁是营销项目的联系人?”
AI 会立即从 HR wiki 或 Slack 历史记录中检索答案。
开始使用 RAG
实施 RAG 是你今天在 AI 战略中可以采取的最具影响力的举措。
它弥合了 LLM 惊人的语言能力与你数据中特定的、专有的价值之间的鸿沟。
你不需要从索引公司的每一份文件开始。
从小处着手。
选择一个数据集——也许是你的客户支持常见问题解答或你的技术文档。
将其加载到向量数据库中。
将其连接到 LLM。
看看当 AI 真正知道自己在谈论什么时会有什么不同。
我们正在从 AI 的炒作阶段迈向实用阶段。
RAG 是使这种实用性成为可能的基础设施。
是时候停止与 AI 闲聊,开始与它并肩工作了。